SpringBoot
Spring boot
微服务
什么是微服务
微服务(Microservice)虽然是当下刚兴起的比较流行的新名词,但本质上来说,微服务并非什么新的概念。
实际上,很多 SOA(面向服务的架构)实施成熟度比较好的企业,已经在使用和实施微服务了。只不过,它们只是在闷声发大财,并不介意是否有一个比较时髦的名词来明确表述 SOA 的这个发展演化趋势罢了。
微服务其实就是服务化思路的一种最佳实践方向,遵循 SOA 的思路,各个企业在服务化治理的道路上走的时间长了,踩的坑多了,整个软件交付链路上各个环节的基础设施逐渐成熟了,微服务自然而然就诞生了。
当然,之所以叫微服务,是与之前的服务化思路和实践相比较而来的。
早些年的服务实现和实施思路是将很多功能从开发到交付都打包成一个很大的服务单元(一般称为 Monolith),而微服务实现和实施思路则更强调功能趋向单一,服务单元小型化和微型化。
如果用“茶壶煮饺子”来打比方的话,原来我们是在一个茶壶里煮很多个饺子,现在(微服务化之后)则基本上是在一个茶壶煮一个饺子,而这些饺子就是服务的功能,茶壶则是将这些服务功能打包交付的服务单元,如图 1 所示。
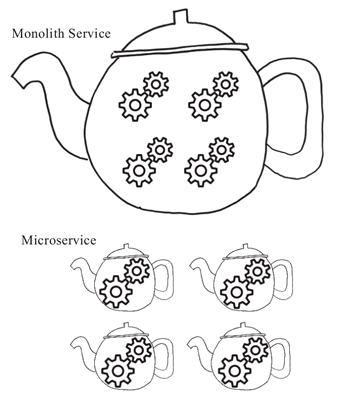
图 1 论茶壶里煮“饺子”的不同形式
所以,从思路和理念上来讲,微服务就是要倡导大家尽量将功能进行拆分,将服务粒度做小,使之可以独立承担对外服务的职责,沿着这个思路开发和交付的软件服务实体就叫作“微服务”,而围绕着这个思路和理念构建的一系列基础设施和指导思想,笔者将它称为“微服务体系”。
微服务是怎么来的?
微服务的概念我们应该大体了解了,那么微服务又是怎么来的?原来将很多功能打包为一个很大的服务单元进行交付的做法不能满足需求吗?
实际上,并非原来“大一统”(Monolith)的服务化实践不能满足要求,也不是不好,只是,它有自己存在的合理场景。
对于 Monolith 服务来说,如果团队不大,软件复杂度不高,那么,使用 Monolith 的形式进行服务化治理是比较合适的,而且,这种方式对运维和各种基础设施的要求也不高。
但是,随着软件系统的复杂度持续飙升,软件交付的效率要求更高,投入的人力以及各项资源越来越多,基于 Monolith 的服务化思路就开始“捉襟见肘”。
在开发阶段,如果我们遵循 Monolith 的服务化理念,通常会将所有功能的实现都统一归到一个开发项目下,但随着功能的膨胀,这些功能一定会分发给不同的研发人员进行开发,造成的后果就是,大家在提交代码的时候频繁冲突并需要解决这些冲突,单一的开发项目成为了开发期间所有人的工作瓶颈。
为了减轻这种苦恼,我们自然会将项目按照要开发的功能拆分为不同的项目,从而负责不同功能的研发人员就可以在自己的代码项目上进行开发,从而解决了大家无法在开发阶段并行开发的苦恼。
到了软件交付阶段,如果我们遵循 Monolith 的服务化理念,那么,我们一定是将所有这些开发阶段并行开发的项目集合到一起进行交付。
这就涉及服务化早期实践中比较有名的“火车模型”,即交付的服务就像一辆火车,而这个服务相关的所有功能对应的项目成果,就是要装上火车车厢的一件件货物,交付的列车只有等到所有项目都开发测试完成后才可以装车出发,完成整个服务的交付。
很显然,只要有一个车厢没有准备好货物(即功能项目未开发测试完成),火车就不能发车,服务就不能交付,这大大降低了服务的交付效率。如果每个功能项目可以各自独立交付,那么就不需要都等同一辆火车,各自出发就可以了。
顺着这个思路,自然而然地,大家逐渐各自独立,每一个功能或者少数相近的功能作为单一项目开发完成后将作为一个独立的服务单元进行交付,从而在服务交付阶段,大家也能够并行不悖,各自演化而不受影响。
所以,随着服务和系统的复杂度逐渐飙升,为了能够在整个软件的交付链路上高效扩展,将独立的功能和服务单元进行拆分,从而形成一个一个的微服务是自然而然发生的事情。
这就像打不同的战役一样,在双方兵力不多、战场复杂度不高的情况下,Monolith 的统一指挥调度方式是合适的。而一旦要打大的战役(类似于系统复杂度提升),双方一定会投入大量的兵力(软件研发团队的规模增长),如果还是在狭小甚至固定的战场上进行厮杀,显然施展不开!
所以,小战役有小战役的打法,大战役有大战役的战法,而微服务实际上就是一种帮助扩展组织能力、提升团队效率的应对“大战役”的方法,它帮助我们从软件开发到交付,进而到团队和组织层面多方位进行扩展。
总的来说,一方面微服务可以帮助我们应对飙升的系统复杂度;另一个方面,微服务可以帮助我们进行更大范围的扩展,从开发阶段项目并行开发的扩展,到交付阶段并行交付的扩展,再到相应的组织结构和组织能力的扩展,皆因微服务而受惠。
微服务的好处(优点)有哪些?
显然,随着系统复杂度的提升,以及对系统扩展性的要求越来越高,微服务化是一个很好的方向,但除此之外,微服务还会给我们带来哪些好处?
独立,独立,还是独立
我们说微服务打响的是各自的独立战争,所以,每一个微服务都是一个小王国,这些微服务跳出了“大一统”(Monolith)王国的统治,开始从各个层面打造自己的独立能力,从而保障自己的小王国可以持续稳固的运转。
首先,在开发层面,每个微服务基本上都是各自独立的项目(project),而对应各自独立项目的研发团队基本上也是独立对应,这样的结构保证了微服务的并行研发,并且各自快速迭代,不会因为所有研发都投入一个近乎单点的项目,从而造成开发阶段的瓶颈。开发阶段的独立,保证了微服务的研发可以高效进行。
服务开发期间的形态,跟服务交付期间的形态原则上是不需要完全高度统一的,即使我们在开发的时候都是各自进行,但交付的时候还是可以一起交付,不过这不是微服务的做法。
在微服务治理体系下,各个微服务交付期间也是各自独立交付的,从而使得每个微服务从开发到交付整条链路上都是独立进行,这大大加快了微服务的迭代和交付效率。
服务交付之后需要部署运行,对微服务来说,它们运行期间也是各自独立的。
微服务独立运行可以带来两个比较明显的好处,第一个就是可扩展性。我们可以快速地添加服务集群的实例,提升整个微服务集群的服务能力,而在传统 Monolith 模式下,为了能够提升服务能力,很多时候必须强化和扩展单一结点的服务能力来达成。如果单结点服务能力已经扩展到了极限,再寻求扩展的话,就得从软件到硬件整体进行重构。
软件行业有句话:“Threads don’t scale,Processes do!”(如果线程不能够扩展,那就去扩展进程),很明确地道出了原来 Monolith 服务与微服务在扩展(Scale)层面的差异。
对于 Java 开发者来说,早些年(当然现在也依然存在),我们遵循 Java EE 规范开发的 Web 应用,都需要以 WAR 包的形式部署到 TOMCAT、Jetty、RESIN 等 Web 容器中运行,即使每个 WAR 包提供的都是独立的微服务,但因为它们都是统一部署运行在一个 Web 容器中,所以扩展能力受限于 Web 容器作为一个进程(process)的现状。
无论如何调整 Web 容器内部实现的线程(thread)设置,还是会受限于 Web 容器整体的扩展能力。所以,现在很多情况下,大家都是一个 TOMCAT 只部署一个 WAR,然后通过复制和扩展多个 TOMCAT 实例来扩展整个应用服务集群。
当然,说到在 TOMCAT 实例中只部署一个 WAR 包这样的做法,实际上不单单只是因为扩展的因素,还涉及微服务运行期间给我们带来的第二个好处,即隔离性。
隔离性实际上是可扩展性的基础,当我们将每个微服务都隔离为独立的运行单元之后,任何一个或者多个微服务的失败都将只影响自己或者少量其他微服务,而不会大面积地波及整个服务运行体系。
在架构设计上有一种实践模式,即隔板模式(Bulkhead Pattern),这种架构设计模式的首要目的就是为了隔离系统中的各个功能单元和实体,使得系统不会因为一个单元或者服务的失败而导致整体失败。
这种思路在造船行业、兵工行业都有类似的应用场景。现在任何大型船舶在设计上都会有隔舱,目的就是即使有少量进水,也可以只将进水部位隔离在小范围,不会扩散而导致船舶大面积进水,从而沉没。当年泰坦尼克号虽然沉了,但不意味着他们没有做隔舱设计,只能说,伤害度已经远远超出隔舱可以提供的基础保障范围。
在坦克的设计上,现在一般也会将弹药舱和乘员舱隔离,从而可以保障当坦克受创之后,将伤害尽量限定在指定区域,尽量减少对车乘成员的伤害。
前面我们提到,现在大家基本上弱化了 Java EE 的 Web 容器早期采用的“一个 Web 容器部署多个 WAR 包”的做法,转而使用“一个 Web 容器只部署一个 WAR 包”的做法,这实际上正是综合考虑了 Web 容器的设计和实现现状与真实需求之后做出的合理实践选择。
这些 Web 容器内部大多通过类加载器(Classloader)以及线程来实现一定程度上的依赖和功能隔离,但这些机制从基因上决定了这些做法不是最好的隔离手段。而进程(Process)拥有天然的隔离特性,所以,一个 WAR 包只部署运行在一个 Web 容器进程中才是最好的隔离方式。
现在回想一下,好像自从各个微服务打响独立战争并且独立之后,无论从哪个层面来看,各自“活”得都挺好。
多语言生态
微服务独立之后,给了对应的团队和组织快速迭代和交付的能力,同时,也给团队和组织带来了更多的灵活性,实际上,对应交付不同微服务的团队或者组织来说,现在可以基于不同的计算机语言生态构建这些微服务,如图 1 所示。
微服务的提供者既可以使用 Java 或者 Go 等静态语言完成微服务的开发和交付,也可以使用 Python 或者 Ruby 等动态语言完成微服务的开发和交付,对于团队内部拥有繁荣且有差异的语言文化来说,多语言生态下的微服务开发和交付将可以最大化的发挥团队和组织内部各成员的优势。
当然,对于多语言生态下的微服务研发来说,有一点需要注意:为了让服务的访问者可以用统一的接口访问所有这些用不同语言开发和交互的微服务,应该尽量统一微服务的服务接口和协议。
在微服务的生态下,互通性应该是需要重点关注的因素,没有互通,不但服务的访问者和用户无法很好地使用这些微服务,微服务和微服务之间也无法相互信赖和互助,这将大大损耗微服务研发体系带来的诸多好处,而多语言生态也会变成一种障碍和负累,而不是益处。
记得时任黑猫宅急便社长的小仓昌男在其所著的《黑猫宅急便的经营学》中提到一个故事,日本国铁曾经采用不同于国际标准的集装箱和铁路规格,然后发现货物的运输效率很低,经过考察发现,原来是货物从国际标准集装箱卸载之后,在通过日本国铁运输之前,需要先拆箱,重新装入日本国铁规格的集装箱,然后装载到日本国铁上进行运输。
但是,如果日本国铁采用国际标准的集装箱规格,那么货物集装箱从远洋轮船上卸载之后就可以直接装上国铁,这将大大加快运输效率(日本,国铁改革后也证明确实如此)。日本国铁在前期采用私有方案时,只关注了自己的利益和效率,舍弃了互通,也带来了效率的低下。
所以,在开发和交付微服务的时候,尤其是在多语言生态下开发和交付微服务,我们从一开始就要将互通性作为首要考虑因素,从而不会因为执迷于某些服务或者系统的单点效率而失去了整个微服务体系的整体效率。
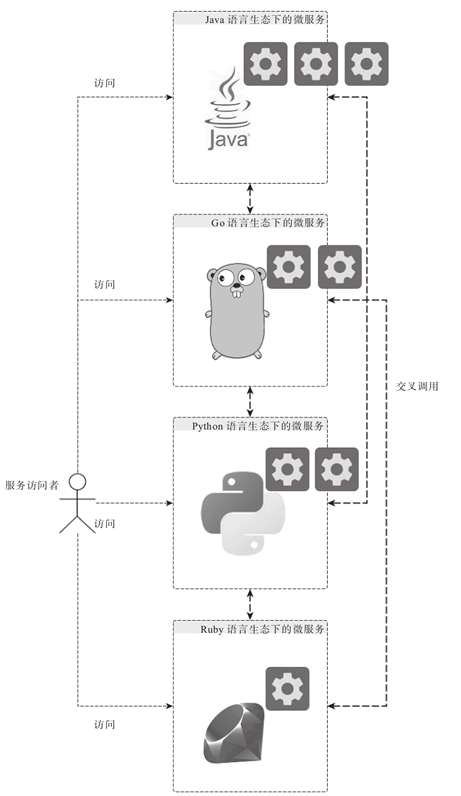
图 1 多语言的微服务生态
实现微服务会带来哪些挑战?
微服务给我们带来的并非只有好处,还有相应的一些挑战。
服务“微”化之后,一个显著的特点就是服务的数量增多了。如果将软件开发和交付也作为一种生产模式看待,那么数量众多的微服务实际上就类似于传统生产线上的产品,而在传统生产模型下,为了能够高效地生产大量产品,通常采用的就是标准化生产。
比如在汽车产业,在福特 T 型车没有出来之前,大多汽车企业的生产效率都不高,而福特在引入标准化生产线之后,福特 T 型车得以大量生产并以低成本优势快速普及。
在其他行业也是同样的道理,个性化生产虽然会深得个别用户的喜欢,但生产成本通常也会很高,生产效率因为受限于个性化需求,也无法从“熟能生巧”中获益,所以,最终用户需要为生产成本和效率付出更多的溢价才能获得最终产品。
而相对于个性化生产来说,标准化生产走的是另一条路,通过生产标准产品,使得整条生产链路可重复,从而提升了生产效率,可以为更广层面的用户提供大量“物美价廉”的标准产品。
微服务的研发和交付其实就类似于产品的生产链路,而数量大这一特点则决定了,我们无法通过个性化的生产模式来支撑整个微服务的交付链路和研发体系。
虽然微服务化之后,我们可以投入相应的人力和团队对应各个微服务的开发和交付,可扩展性上绝对没有问题,但这不意味着现实情况下我们就能这样做,因为这些都涉及人力和资源成本,而这往往是受限的。所以,使用标准化的思路来开发和交付微服务就变成了自然而然的选择:
通过标准化,我们可以重复使用开发阶段打造的一系列环境和工具支持。
通过标准化,我们可以复用支持整个微服务交付链路的各项基础设施。
通过标准化,我们可以减少采购差异导致的成本上升,同时更加高效地利用硬件资源。
通过标准化,我们可以用标准的协议和格式来治理和维护数量庞大的微服务。
如果你还对使用标准化的思路来构建微服务体系存有疑惑,那么,不妨再结合微服务的多语言生态特性思考一番:
增加一种语言生态用于微服务的开发和交付,我们是否要围绕着这种语言生态和微服务的需求重新搭建一套研发/测试环境?
我们是否还要围绕着这种语言生态打造一系列的工具来提升日常开发的效率?
增加一种语言生态,我们是不是还要围绕这种语言生态搭建一套针对微服务的交付链路基础设施?
增加一种语言生态,我们是否还要围绕它提供特定的硬件环境以及运维支撑工具和平台?
多语言生态虽然灵活度高了,不同语种和思路的团队成员也能够百花齐放了,但是不是也同样带来了以上一系列的成本?
所以,很多事情你能做,并不意味着你一定要做。适度的收缩语言生态的选择范围,并围绕主要的语言生态构建一套标准化的微服务交付体系,或许是更为合理的做法。
要实施高效可重复的标准化微服务生产,我们需要有类似传统行业生产线的基础设施。否则,高效可重复的开发和交付大量的微服务就无从谈起,所以,完备的微服务研发和交付体系基础设施建设就成为了实施微服务的终极挑战。
一个公司或者组织要很好地或者说成熟地实施微服务化战略,为交付链路提供完备支撑的基础设施建设必不可少!
Spring IoC介绍
有部分 Java 开发者对 IoC(Inversion Of Control)和 DI(Dependency Injection)的概念有些混淆,认为二者是对等的。
IoC 其实有两种方式,一种就是 DI,而另一种是 DL,即 Dependency Lookup(依赖查找),前者是当前软件实体被动接受其依赖的其他组件被 IoC 容器注入,而后者则是当前软件实体主动去某个服务注册地查找其依赖的那些服务,概念之间的关系如图 1 所示可能更贴切些。
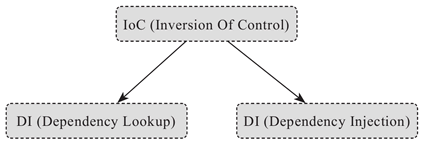
图 1 IoC相关概念示意图
我们通常提到的 Spring IoC,实际上是指 Spring 框架提供的 IoC 容器实现(IoC Container),而使用 Spring IoC 容器的一个典型代码片段就是:
public class App {
public static void main(String[] args) {
ApplicationContext context = new FileSystemXmlApplication-Context("...");
// ...
MockService service = context.getBean(MockService.class);
service.doSomething();
}
}任何一个使用 Spring 框架构建的独立的 Java 应用(Standalone Java Application),通常都会存在一行类似于context.getBean(...);的代码。
实际上,这行代码做的就是 DL 的工作,而构建的任何一种 IoC 容器背后(比如 BeanFactory 或者 ApplicationContext)发生的事情,则更多是 DI 的过程(也可能有部分 DL 的逻辑用于对接遗留系统)。
Spring 的 IoC 容器中发生的事情其实也很简单,总结下来即两个阶段:
- 采摘和收集“咖啡豆”(bean)
- 研磨和烹饪咖啡
Spring IoC 容器的依赖注入工作可以分为两个阶段:
1)收集和注册
第一个阶段可以认为是构建和收集 bean 定义的阶段,在这个阶段中,我们可以通过 XML 或者 Java 代码的方式定义一些 bean,然后通过手动组装或者让容器基于某些机制自动扫描的形式,将这些 bean 定义收集到 IoC 容器中。
假设我们以 XML 配置的形式来收集并注册单一 bean,一般形式如下:
<bean id="mockService" class="..MockServiceImpl"> ...</bean>如果嫌逐个收集 bean 定义麻烦,想批量地收集并注册到 IoC 容器中,我们也可以通过 XML Schema 形式的配置进行批量扫描并采集和注册:
<context:component-scan base-package="com.keevol">注意基于 JavaConfig 形式的收集和注册,不管是单一还是批量,后面我们都会单独提及。
2)分析和组装
当第一阶段工作完成后,我们可以先暂且认为 IoC 容器中充斥着一个个独立的 bean,它们之间没有任何关系。
但实际上,它们之间是有依赖关系的,所以,IoC 容器在第二阶段要干的事情就是分析这些已经在 IoC 容器之中的 bean,然后根据它们之间的依赖关系先后组装它们。
如果 IoC 容器发现某个 bean 依赖另一个 bean,它就会将这另一个 bean 注入给依赖它的那个 bean,直到所有 bean 的依赖都注入完成,所有 bean 都“整装待发”,整个 IoC 容器的工作即算完成。
至于分析和组装的依据,Spring 框架最早是通过 XML 配置文件的形式来描述 bean 与 bean 之间的关系的,随着 Java 业界研发技术和理念的转变,基于 Java 代码和 Annotation 元信息的描述方式也日渐兴盛(比如 @Autowired 和 @Inject),但不管使用哪种方式,都只是为了简化绑定逻辑描述的各种“表象”,最终都是为本阶段的最终目的服务。
很多 Java 开发者一定认为 Spring 的 XML 配置文件是一种配置(Configuration),但本质上,这些配置文件更应该是一种代码形式,XML 在这里其实可以看作一种 DSL( Domain Specific Language 的缩写,中文翻译为领域特定语言),它用来表述的是 bean 与 bean 之间的依赖绑定关系,如果没有 IoC 容器就要自己写代码新建(new)对象并配置(set)依赖。
Spring JavaConfig
Java 5 的推出,加上当年基于纯 Java Annotation 的依赖注入框架 Guice 的出现,使得 Spring 框架及其社区也“顺应民意”,推出并持续完善了基于 Java 代码和 Annotation 元信息的依赖关系绑定描述方式,即 JavaConfig 项目。
基于 JavaConfig 方式的依赖关系绑定描述基本上映射了最早的基于 XML 的配置方式,比如:
1)表达形式层面
基于 XML 的配置方式是这样的:
<?xml version="1.0" encoding="UTF-8"?><beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd">
<!-- bean定义 -->
</beans>而基于 JavaConfig 的配置方式是这样的:
@Configuration
public class MockConfiguration{
// bean定义
} 任何一个标注了 @Configuration 的 Java 类定义都是一个 JavaConfig 配置类。
2)注册 bean 定义层面
基于 XML 的配置形式是这样的:
<bean id="mockService" class="..MockServiceImpl"> ...</bean>而基于 JavaConfig 的配置形式是这样的:
@Configuration
public class MockConfiguration {
@Bean
public MockService mockService() {
return new MockServiceImpl();
}
}任何一个标注了 @Bean 的方法,其返回值将作为一个 bean 定义注册到 Spring 的 IoC 容器,方法名将默认成为该 bean 定义的 id。
3)表达依赖注入关系层面
为了表达 bean 与 bean 之间的依赖关系,在 XML 形式中一般是这样的:
<bean id="mockService" class="..MockServiceImpl">
<property name="dependencyService" ref="dependencyService" />
</bean>
<bean id="dependencyService" class="DependencyServiceImpl" /> 而在 JavaConfig 中则是这样的:
@Configuration
public class MockConfiguration {
@Bean
public MockService mockService() {
return new MockServiceImpl(dependencyService());
}
@Bean
public DependencyService dependencyService() {
return new DependencyServiceImpl();
}
}如果一个 bean 的定义依赖其他 bean,则直接调用对应 JavaConfig 类中依赖 bean 的创建方法就可以了。
在 JavaConfig 形式的依赖注入过程中,我们使用方法调用的形式注入依赖,如果这个方法返回的对象实例只被一个 bean 依赖注入,那也还好,如果多于一个 bean 需要依赖这个方法调用返回的对象实例,那是不是意味着我们就会创建多个同一类型的对象实例?
从代码表述的逻辑来看,直觉上应该是会创建多个同一类型的对象实例,但实际上最终结果却不是这样,依赖注入的都是同一个 Singleton 的对象实例,那这是如何做到的?
笔者一开始以为 Spring 框架会通过解析 JavaConfig 的代码结构,然后通过解析器转换加上反射等方式完成这一目的,但实际上 Spring 框架的设计和实现者采用了另一种更通用的方式,这在 Spring 的参考文档中有说明。即通过拦截配置类的方法调用来避免多次初始化同一类型对象的问题,一旦拥有拦截逻辑的子类发现当前方法没有对应的类型实例时才会去请求父类的同一方法来初始化对象实例,否则直接返回之前的对象实例。
所以,原来 Spring IoC 容器中有的特性(features)在 JavaConfig 中都可以表述,只是换了一种形式而已,而且,通过声明相应的 Java Annotation 反而“内聚”一处,变得更加简洁明了了。
那些高曝光率的 Annotation
至于 @Configuration,我想前面已经提及过了,这里不再赘述,下面我们看几个其他比较常见的 Annotation,便于为后面更好地理解 SpringBoot 框架的奥秘做准备。
1. @ComponentScan
@ComponentScan 对应 XML 配置形式中的 <context:component-scan> 元素,用于配合一些元信息 Java Annotation,比如 @Component 和 @Repository 等,将标注了这些元信息 Annotation 的 bean 定义类批量采集到 Spring 的 IoC 容器中。
我们可以通过 basePackages 等属性来细粒度地定制 @ComponentScan 自动扫描的范围,如果不指定,则默认 Spring 框架实现会从声明 @ComponentScan 所在类的 package 进行扫描。
@ComponentScan 是 SpringBoot 框架魔法得以实现的一个关键组件,大家可以重点关注,我们后面还会遇到它。
2. @PropertySource 与 @PropertySources
@PropertySource 用于从某些地方加载 *.properties 文件内容,并将其中的属性加载到 IoC 容器中,便于填充一些 bean 定义属性的占位符(placeholder),当然,这需要 PropertySourcesPlaceholderConfigurer 的配合。
如果我们使用 Java 8 或者更高版本开发,那么,我们可以并行声明多个 @PropertySource:
@Configuration
@PropertySource("classpath:1.properties")
@PropertySource("classpath:2.properties")
@PropertySource("...")
public class XConfiguration{
...
}如果我们使用低于 Java 8 版本的 Java 开发 Spring 应用,又想声明多个 @PropertySource,则需要借助 @PropertySources 的帮助了,代码如下所示:
@PropertySources({ @PropertySource("classpath:1.properties"), @PropertySource("classpath:2.properties"), ...})
public class XConfiguration{
...
}3. @Import 与 @ImportResource
在 XML 形式的配置中,我们通过 <import resource="XXX.xml"/> 的形式将多个分开的容器配置合到一个配置中,在 JavaConfig 形式的配置中,我们则使用 @Import 这个 Annotation 完成同样目的:
@Configuration
@Import(MockConfiguration.class)
public class XConfiguration {
...
}@Import 只负责引入 JavaConfig 形式定义的 IoC 容器配置,如果有一些遗留的配置或者遗留系统需要以 XML 形式来配置(比如 dubbo 框架),我们依然可以通过 @ImportResource 将它们一起合并到当前 JavaConfig 配置的容器中。
SpringBoot是什么?
随着动态语言的流行(Ruby、Groovy、Scala、Node.js),Java 的开发显得格外的笨重,繁多的配置、低下的开发效率、复杂的部署流程以及第三方技术集成难度大。
在上述环境下,Spring Boot 应运而生。它使用“习惯优于配置”(项目中存在大量的配置,此外还内置一个习惯性的配置,让你无须手动进行配置)的理念让你的项目快速运行起来。
使用 Spring Boot 很容易创建一个独立运行(运行 jar,内嵌 Servlet 容器)、准生产级别的基于 Spring 框架的项目,使用 Spring Boot 你可以不用或者只需要很少的 Spring 配置。
Spring Boot 核心功能
1)独立运行的 Spring 项目
Spring Boot 可以以 jar 包的形式独立运行,运行一个 Spring Boot 项目只需通过 java–jar xx.jar 来运行。
2)内嵌 Servlet 容器
Spring Boot 可选择内嵌 Tomcat、Jetty 或者 Undertow,这样我们无须以 war 包形式部署项目。
3)提供 starter 简化 Maven 配置
Spring 提供了一系列的 starter pom 来简化 Maven 的依赖加载,例如,当你使用了spring-boot-starter-web 时,会自动加入如图 1 所示的依赖包。
4)自动配置 Spring
Spring Boot 会根据在类路径中的 jar 包、类,为 jar 包里的类自动配置 Bean,这样会极大地减少我们要使用的配置。当然,Spring Boot 只是考虑了大多数的开发场景,并不是所有的场景,若在实际开发中我们需要自动配置 Bean,而 Spring Boot 没有提供支持,则可以自定义自动配置。
5)准生产的应用监控
Spring Boot 提供基于 http、ssh、telnet 对运行时的项目进行监控。
6)无代码生成和 xml 配置
Spring Boot 的神奇的不是借助于代码生成来实现的,而是通过条件注解来实现的,这是 Spring 4.x 提供的新特性。Spring 4.x 提倡使用 Java 配置和注解配置组合,而 Spring Boot 不需要任何 xml 配置即可实现 Spring 的所有配置。
Spring Boot的优缺点
1)优点
- 快速构建项目。
- 对主流开发框架的无配置集成。
- 项目可独立运行,无须外部依赖Servlet容器。
- 提供运行时的应用监控。
- 极大地提高了开发、部署效率。
- 与云计算的天然集成。
2)缺点
- 版本迭代速度很快,一些模块改动很大。
- 由于不用自己做配置,报错时很难定位。
- 网上现成的解决方案比较少。
SpringBoot快速搭建
我们说 SpringBoot 是 Spring 框架对“约定优先于配置(Convention Over Configuration)”理念的最佳实践的产物,一个典型的 SpringBoot 应用本质上其实就是一个基于 Spring 框架的应用,而如果大家对 Spring 框架已经了如指掌,那么,在我们一步步揭开 SpringBoot 微框架的面纱之后,大家就会发现“阳光之下,并无新事”。
一个典型的 SpringBoot 应用长什么样子呢?下面我们快速搭建一个SpringBoot 应用。
- 打开浏览器,输入网址 http://start.spring.io/ ,如图 1 所示:
图 1 spring.io页面
- 创建一个最简单的依赖 Web 模块的 SpringBoot 应用,填写项目信息,如图 1 所示。
我们在此以 Maven 作为项目构建方式,Spring Boot 还支持以 Gradle 作为项目构建工具。部署形式以 jar 包形式,当然也可以用传统的 war 包形式。Spring Boot 选择2.1.6,Spring boot 还支持以 Groovy 语言开发,应用中选择 Java 作为开发语言。
- 选择完之后,下载代码,如图 2 所示:
图 2 下载代码
一般情况下,我们会得到一个 SpringBoot 应用的启动类,如下面代码所示:
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}所有的 SpringBoot 无论怎么定制,本质上与上面的启动类代码是一样的,而以上代码示例中,Annotation 定义(@SpringBootApplication)和类定义(SpringApplication.run)最为耀眼,那么,要揭开 SpringBoot 应用的奥秘,很明显的,我们只要先从这两位开始就可以了。
SpringBoot中@SpringBootApplication注解的三体结构解析
@SpringBootApplication 是一个“三体”结构,实际上它是一个复合 Annotation:
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@Configuration
@EnableAutoConfiguration
@ComponentScan
public @interface SpringBootApplication{...}虽然它的定义使用了多个 Annotation 进行元信息标注,但实际上对于 SpringBoot 应用来说,重要的只有三个 Annotation,而“三体”结构实际上指的就是这三个 Annotation:
@Configuration@EnableAutoConfiguration@ComponentScan
所以,如果我们使用如下的 SpringBoot 启动类,整个 SpringBoot 应用依然可以与之前的启动类功能对等:
@Configuration
@EnableAutoConfiguration
@ComponentScan
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}但每次都写三个 Annotation 显然过于繁琐,所以写一个 @SpringBootApplication 这样的一站式复合 Annotation 显然更方便些。
@Configuration 创世纪
这里的 @Configuration 对我们来说并不陌生,它就是 JavaConfig 形式的 Spring IoC 容器的配置类使用的那个 @Configuration,既然 SpringBoot 应用骨子里就是一个 Spring 应用,那么,自然也需要加载某个 IoC 容器的配置,而 SpringBoot 社区推荐使用基于 JavaConfig 的配置形式,所以,很明显,这里的启动类标注了 @Configuration 之后,本身其实也是一个 IoC 容器的配置类!
很多 SpringBoot 的代码示例都喜欢在启动类上直接标注 @Configuration 或者 @SpringBootApplication,对于初接触 SpringBoot 的开发者来说,其实这种做法不便于理解,如果我们将上面的 SpringBoot 启动类拆分为两个独立的 Java 类,整个形势就明朗了:
@Configuration
@EnableAutoConfiguration
@ComponentScan
public class DemoConfiguration {
@Bean
public Controller controller() {
return new Controller();
}
}
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoConfiguration.class, args);
}
}所以,启动类 DemoApplication 其实就是一个标准的 Standalone 类型 Java 程序的 main 函数启动类,没有什么特殊的。而 @Configuration 标注的 DemoConfiguration 定义其实也是一个普通的 JavaConfig 形式的 IoC 容器配置类。
@EnableAutoConfiguration 的功效
@EnableAutoConfiguration 其实也没啥“创意”,各位是否还记得 Spring 框架提供的各种名字为 @Enable 开头的 Annotation 定义?
比如 @EnableScheduling、@EnableCaching、@EnableMBeanExport 等,@EnableAutoConfiguration 的理念和“做事方式”其实一脉相承,简单概括一下就是,借助 @Import 的支持,收集和注册特定场景相关的 bean 定义:
@EnableScheduling是通过@Import将 Spring 调度框架相关的 bean 定义都加载到 IoC 容器。@EnableMBeanExport是通过@Import将 JMX 相关的 bean 定义加载到 IoC 容器。
而 @EnableAutoConfiguration 也是借助 @Import 的帮助,将所有符合自动配置条件的 bean 定义加载到 IoC 容器,仅此而已!
@EnableAutoConfiguration 作为一个复合 Annotation,其自身定义关键信息如下:
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@AutoConfigurationPackage
@Import(EnableAutoConfigurationImportSelector.class)
public @interface EnableAutoConfiguration {...}其中,最关键的要属 @Import(EnableAutoConfigurationImportSelector.class),借助 EnableAutoConfigurationImportSelector,@EnableAutoConfiguration 可以帮助 SpringBoot 应用将所有符合条件的 @Configuration 配置都加载到当前 SpringBoot 创建并使用的 IoC 容器,就跟一只“八爪鱼”一样(如图 1 所示)。
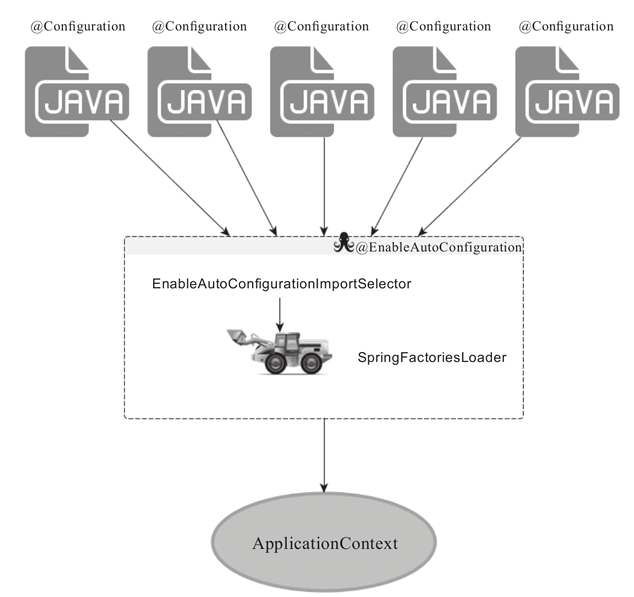
图 1 EnableAutoConfiguration得以生效的关键组件关系图
借助于 Spring 框架原有的一个工具类:SpringFactoriesLoader 的支持,@EnableAutoConfiguration 可以“智能”地自动配置功效才得以大功告成!
SpringFactoriesLoader详解
SpringFactoriesLoader 属于 Spring 框架私有的一种扩展方案(类似于 Java 的 SPI 方案 java.util.ServiceLoader),其主要功能就是从指定的配置文件 META-INF/spring.factories 加载配置,spring.factories 是一个典型的 java properties 文件,配置的格式为 Key=Value 形式,只不过 Key 和 Value 都是 Java 类型的完整类名(Fully qualified name),比如:
example.MyService=example.MyServiceImpl1,example.MyServiceImpl2 然后框架就可以根据某个类型作为 Key 来查找对应的类型名称列表了:
public abstract class SpringFactoriesLoader {
// ...
public static <T> List<T> loadFactories(Class<T> factoryClass, ClassLoader classLoader) {
...
}
public static List<String> loadFactoryNames(Class<?> factoryClass, ClassLoader classLoader) {
...
}
// ...
}对于 @EnableAutoConfiguration 来说,SpringFactoriesLoader 的用途稍微不同一些,其本意是为了提供 SPI 扩展的场景,而在 @EnableAutoConfiguration 的场景中,它更多是提供了一种配置查找的功能支持,即根据 @EnableAutoConfiguration 的完整类名 org.springframework.boot.autoconfigure.EnableAutoConfiguration 作为查找的 Key,获取对应的一组 @Configuration 类:
org.springframework.boot.autoconfigure.EnableAutoConfiguration=
\org.springframework.boot.autoconfigure.admin.SpringApplicationAdmin- JmxAutoConfiguration,
\org.springframework.boot.autoconfigure.aop.AopAutoConfiguration,
\org.springframework.boot.autoconfigure.amqp.RabbitAutoConfiguration,
\org.springframework.boot.autoconfigure.MessageSourceAutoConfiguration,
\org.springframework.boot.autoconfigure.PropertyPlaceholderAuto- Configuration,
\org.springframework.boot.autoconfigure.batch.BatchAutoConfiguration,
\org.springframework.boot.autoconfigure.cache.CacheAutoConfiguration,
\org.springframework.boot.autoconfigure.cassandra.CassandraAuto-Configuration,
\org.springframework.boot.autoconfigure.cloud.CloudAutoConfiguration,
\org.springframework.boot.autoconfigure.context.ConfigurationProperties-AutoConfiguration,
\org.springframework.boot.autoconfigure.dao.PersistenceException-TranslationAutoConfiguration,
\org.springframework.boot.autoconfigure.data.cassandra.Cassandra-DataAutoConfiguration,
\org.springframework.boot.autoconfigure.data.cassandra.Cassandra-RepositoriesAutoConfiguration,
\...以上是从 SpringBoot 的 autoconfigure 依赖包中的 META-INF/spring.factories 配置文件中摘录的一段内容,可以很好地说明问题。
所以,@EnableAutoConfiguration 自动配置的魔法其实就变成了:从 classpath 中搜寻所有 META-INF/spring.factories 配置文件,并将其中 org.springframework.boot.autoconfigure.EnableAutoConfiguration 对应的配置项通过反射(Java Reflection)实例化为对应的标注了 @Configuration 的 JavaConfig 形式的 IoC 容器配置类,然后汇总为一个并加载到 IoC 容器。
可有可无的@ComponentScan
为啥说 @ComponentScan 是可有可无的?
因为原则上来说,作为 Spring 框架里的“老一辈革命家”,@ComponentScan 的功能其实就是自动扫描并加载符合条件的组件或 bean 定义,最终将这些 bean 定义加载到容器中。加载 bean 定义到 Spring 的 IoC 容器,我们可以手工单个注册,不一定非要通过批量的自动扫描完成,所以说 @ComponentScan 是可有可无的。
对于 SpringBoot 应用来说,同样如此,比如我们本章的启动类:
@Configuration
@EnableAutoConfiguration
@ComponentScan
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}如果我们当前应用没有任何 bean 定义需要通过 @ComponentScan 加载到当前 SpringBoot 应用对应使用的 IoC 容器,那么,除去 @ComponentScan 的声明,当前 SpringBoot 应用依然可以照常运行,功能对等。
SpringApplication.run执行流程详解
SpringApplication 将一个典型的 Spring 应用启动的流程“模板化”(这里是动词),在没有特殊需求的情况下,默认模板化后的执行流程就可以满足需求了但有特殊需求也没关系,SpringApplication 在合适的流程结点开放了一系列不同类型的扩展点,我们可以通过这些扩展点对 SpringBoot 程序的启动和关闭过程进行扩展。
最“肤浅”的扩展或者配置是 SpringApplication 通过一系列设置方法(setters)开放的定制方式,比如,我们之前的启动类的 main 方法中只有一句:
SpringApplication.run(DemoApplication.class,args);
但如果我们想通过 SpringApplication 的一系列设置方法来扩展启动行为,则可以用如下方式进行:
public class DemoApplication {
public static void main(String[] args) {
// SpringApplication.run(DemoConfiguration.class, args);
SpringApplication bootstrap = new SpringApplication(Demo - Configuration.class);
bootstrap.setBanner(new Banner() {
@Override
public void printBanner(Environment environment, Class<?> aClass, PrintStream printStream) {
// 比如打印一个我们喜欢的ASCII Arts字符画
}
});
bootstrap.setBannerMode(Banner.Mode.CONSOLE);
// 其他定制设置...
bootstrap.run(args);
}
}设置自定义 banner 最简单的方式其实是把 ASCII Art 字符画放到一个资源文件,然后通过 ResourceBanner 来加载:
bootstrap.setBanner(new ResourceBanner(new ClassPathResource("banner.txt")));
这里也可以直接在 src/main/resource 下新建 banner.txt
可以去下面网站(喜欢哪个用哪个)去生成自己的个性 banner,再拷贝过去就行啦:
- https://www.bootschool.net/ascii
- [http://patorjk.com/software/taag/#p=display&f=Graffiti&t=Type Something](http://patorjk.com/software/taag/#p=display&f=Graffiti&t=Type Something )
大部分情况下,SpringApplication 已经提供了很好的默认设置,所以,我们不再对这些表层进行探究了,因为对表层之下的东西进行探究才是我们的最终目的。
深入探索 SpringApplication 执行流程
SpringApplication 的 run 方法的实现是我们本次旅程的主要线路,该方法的主要流程大体可以归纳如下:
如果我们使用的是 SpringApplication 的静态 run 方法,那么,这个方法里面首先需要创建一个 SpringApplication 对象实例,然后调用这个创建好的 SpringApplication 的实例 run方 法。在 SpringApplication 实例初始化的时候,它会提前做几件事情:
根据 classpath 里面是否存在某个特征类(
org.springframework.web.context.ConfigurableWebApplicationContext)来决定是否应该创建一个为 Web 应用使用的 ApplicationContext 类型,还是应该创建一个标准 Standalone 应用使用的 ApplicationContext 类型。使用 SpringFactoriesLoader 在应用的 classpath 中查找并加载所有可用的 ApplicationContextInitializer。
使用 SpringFactoriesLoader 在应用的 classpath 中查找并加载所有可用的 ApplicationListener。
推断并设置 main 方法的定义类。
SpringApplication 实例初始化完成并且完成设置后,就开始执行 run 方法的逻辑了,方法执行伊始,首先遍历执行所有通过 SpringFactoriesLoader 可以查找到并加载的 SpringApplicationRunListener,调用它们的 started() 方法,告诉这些 SpringApplicationRunListener,“嘿,SpringBoot 应用要开始执行咯!”。
创建并配置当前 SpringBoot 应用将要使用的 Environment(包括配置要使用的 PropertySource 以及 Profile)。
遍历调用所有 SpringApplicationRunListener 的 environmentPrepared()的方法,告诉它们:“当前 SpringBoot 应用使用的 Environment 准备好咯!”。
如果 SpringApplication的showBanner 属性被设置为 true,则打印 banner(SpringBoot 1.3.x版本,这里应该是基于 Banner.Mode 决定 banner 的打印行为)。这一步的逻辑其实可以不关心,我认为唯一的用途就是“好玩”(Just For Fun)。
根据用户是否明确设置了applicationContextClass 类型以及初始化阶段的推断结果,决定该为当前 SpringBoot 应用创建什么类型的 ApplicationContext 并创建完成,然后根据条件决定是否添加 ShutdownHook,决定是否使用自定义的 BeanNameGenerator,决定是否使用自定义的 ResourceLoader,当然,最重要的,将之前准备好的 Environment 设置给创建好的 ApplicationContext 使用。
ApplicationContext 创建好之后,SpringApplication 会再次借助 Spring-FactoriesLoader,查找并加载 classpath 中所有可用的 ApplicationContext-Initializer,然后遍历调用这些 ApplicationContextInitializer 的 initialize(applicationContext)方法来对已经创建好的 ApplicationContext 进行进一步的处理。
遍历调用所有 SpringApplicationRunListener 的 contextPrepared()方法,通知它们:“SpringBoot 应用使用的 ApplicationContext 准备好啦!”
最核心的一步,将之前通过
@EnableAutoConfiguration获取的所有配置以及其他形式的 IoC 容器配置加载到已经准备完毕的 ApplicationContext。遍历调用所有 SpringApplicationRunListener 的 contextLoaded() 方法,告知所有 SpringApplicationRunListener,ApplicationContext “装填完毕”!
调用 ApplicationContext 的 refresh() 方法,完成 IoC 容器可用的最后一道工序。
查找当前 ApplicationContext 中是否注册有 CommandLineRunner,如果有,则遍历执行它们。
正常情况下,遍历执行 SpringApplicationRunListener 的 finished() 方法,告知它们:“搞定!”。(如果整个过程出现异常,则依然调用所有 SpringApplicationRunListener 的 finished() 方法,只不过这种情况下会将异常信息一并传入处理)。
至此,一个完整的 SpringBoot 应用启动完毕!
整个过程看起来冗长无比,但其实很多都是一些事件通知的扩展点,如果我们将这些逻辑暂时忽略,那么,其实整个 SpringBoot 应用启动的逻辑就可以压缩到极其精简的几步,如图 1 所示。
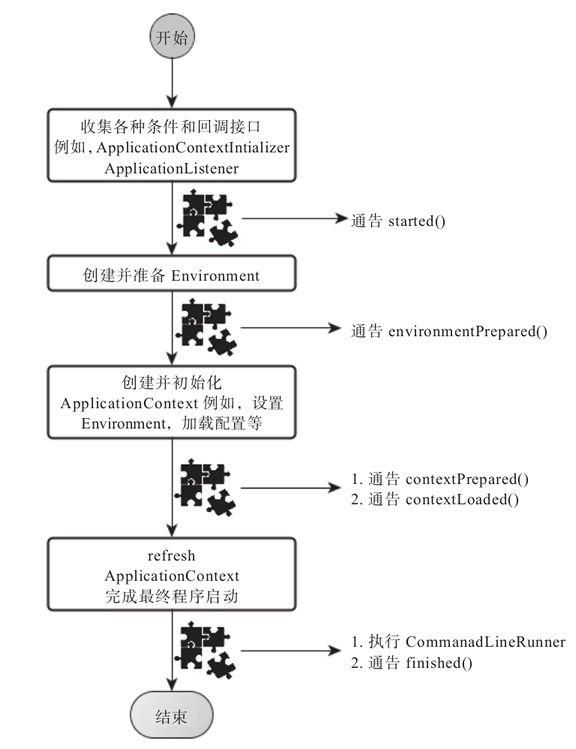
图 1 SpringBoot应用启动步骤简要示意图
前后对比我们就可以发现,其实 SpringApplication 提供的这些各类扩展点近乎“喧宾夺主”,占据了一个 Spring 应用启动逻辑的大部分“江山”,除了初始化并准备好 ApplicationContext,剩下的大部分工作都是通过这些扩展点完成的,所以,我们接下来对各类扩展点进行逐一剖析。
SpringApplicationRunListener
SpringApplicationRunListener 是一个只有 SpringBoot 应用的 main 方法执行过程中接收不同执行时点事件通知的监听者:
public interface SpringApplicationRunListener {
void started();
void environmentPrepared(ConfigurableEnvironment environment);
void contextPrepared(ConfigurableApplicationContext context);
void contextLoaded(ConfigurableApplicationContext context);
void finished(ConfigurableApplicationContext context, Throwable exception);
}对于我们来说,基本没什么常见的场景需要自己实现一个 Spring-ApplicationRunListener,即使 SpringBoot 默认也只是实现了一个 org.springframework.boot.context.event.EventPublishingRunListener,用于在 SpringBoot 启动的不同时点发布不同的应用事件类型(ApplicationEvent),如果有哪些 ApplicationListener 对这些应用事件感兴趣,则可以接收并处理。
假设我们真的有场景需要自定义一个 SpringApplicationRunListener 实现,那么有一点需要注意,即任何一个 SpringApplicationRunListener 实现类的构造方法(Constructor)需要有两个构造参数,一个构造参数的类型就是我们的 org.springframework.boot.SpringApplication,另外一个就是 args 参数列表的 String[]:
public class DemoSpringApplicationRunListener implements SpringApplicationRunListener {
@Override
public void started() {
// do whatever you want to do
}
@Override
public void environmentPrepared(ConfigurableEnvironment environment) {
// do whatever you want to do
}
@Override
public void contextPrepared(ConfigurableApplicationContext context) {
// do whatever you want to do
}
@Override
public void contextLoaded(ConfigurableApplicationContext context) {
// do whatever you want to do
}
@Override
public void finished(ConfigurableApplicationContext context, Throwable exception) {
// do whatever you want to do
}
}之后,我们可以通过 SpringFactoriesLoader 立下的规矩,在当前 SpringBoot 应用的 classpath 下的 META-INF/spring.factories 文件中进行类似如下的配置:
org.springframework.boot.SpringApplicationRunListener=\com.keevol.springboot.demo.DemoSpringApplicationRunListener然后 SpringApplication 就会在运行的时候调用它啦!
ApplicationListener
ApplicationListener 其实是老面孔,属于 Spring 框架对 Java 中实现的监听者模式的一种框架实现,这里唯一值得着重强调的是,对于初次接触 SpringBoot,但对 Spring 框架本身又没有过多接触的开发者来说,可能会将这个名字与 SpringApplicationRunListener 混淆。
关于 ApplicationListener 我们就不做过多介绍了,如果感兴趣,请参考 Spring 框架相关的资料和书籍。
如果我们要为 SpringBoot 应用添加自定义的 ApplicationListener,有两种方式:
- 通过
SpringApplication.addListeners(..)或者SpringApplication.setListeners(..)方法添加一个或者多个自定义的 ApplicationListener。 - 借助 SpringFactoriesLoader 机制,在
META-INF/spring.factories文件中添加配置(以下代码是为 SpringBoot 默认注册的 ApplicationListener 配置)。
org.springframework.context.ApplicationListener=
\org.springframework.boot.builder.ParentContextCloserApplicationListener,
\org.springframework.boot.cloudfoundry.VcapApplicationListener,
\org.springframework.boot.context.FileEncodingApplicationListener,
\org.springframework.boot.context.config.AnsiOutputApplicationListener,
\org.springframework.boot.context.config.ConfigFileApplicationListener,
\org.springframework.boot.context.config.DelegatingApplicationListener,
\org.springframework.boot.liquibase.LiquibaseServiceLocatorApplicat-ionListener,
\org.springframework.boot.logging.ClasspathLoggingApplicationListener,
\org.springframework.boot.logging.LoggingApplicationListener关于 ApplicationListener,我们就说这些。
ApplicationContextInitializer
ApplicationContextInitializer 也是 Spring 框架原有的概念,这个类的主要目的就是在 ConfigurableApplicationContext 类型(或者子类型)的 ApplicationContext 做 refresh 之前,允许我们对 ConfigurableApplicationContext 的实例做进一步的设置或者处理。
实现一个 ApplicationContextInitializer 很简单,因为它只有一个方法需要实现:
public class DemoApplicationContextInitializer implements ApplicationContextInitializer {
@Override
public void initialize(ConfigurableApplicationContext applicationContext) {
// do whatever you want with applicationContext,
// e.g.
applicationContext.registerShutdownHook();
}
}不过,一般情况下我们基本不会需要自定义一个 ApplicationContext-Initializer,即使 SpringBoot 框架默认也只是注册了三个实现:
org.springframework.context.ApplicationContextInitializer=
\org.springframework.boot.context.ConfigurationWarningsApplication-ContextInitializer,
\org.springframework.boot.context.ContextIdApplicationContextInitia-lizer,
\org.springframework.boot.context.config.DelegatingApplicationContex-tInitializer如果我们真的需要自定义一个 ApplicationContextInitializer,那么只要像上面这样,通过 SpringFactoriesLoader 机制进行配置,或者通过 SpringApplication.addInitializers(..)设置即可。
CommandLineRunner
CommandLineRunner 是很好的扩展接口,不是 Spring 框架原有的“宝贝”,它属于 SpringBoot 应用特定的回调扩展接口。源码如下所示:
public interface CommandLineRunner {
void run(String... args) throws Exception;
}CommandLineRunner 需要大家关注的其实就两点:
所有 CommandLineRunner 的执行时点在 SpringBoot 应用的 Application-Context 完全初始化开始工作之后(可以认为是 main 方法执行完成之前最后一步)。
只要存在于当前 SpringBoot 应用的 ApplicationContext 中的任何 Command-LineRunner,都会被加载执行(不管你是手动注册这个 CommandLineRunner 到 IoC 容器,还是自动扫描进去的)。
与其他几个扩展点接口类型相似,建议 CommandLineRunner 的实现类使用 @org.springframework.core.annotation.Order 进行标注或者实现 org.springframework.core.Ordered 接口,便于对它们的执行顺序进行调整,这其实十分重要,我们不希望顺序不当的 CommandLineRunner 实现类阻塞了后面其他 CommandLineRunner 的执行。
SpringBoot的自动配置
在教程《@SpringBootApplication注解》中讲到 @EnableAutoConfiguration 可以借助 SpringFactoriesLoader 这个特性将标注了 @Configuration 的 JavaConfig 类“一股脑儿”的汇总并加载到最终的 ApplicationContext,不过,这其实只是“简化版”的说明。
实际上,基于 @EnableAutoConfiguration 的自动配置功能拥有更加强大的调控能力,通过配合比如基于条件的配置能力或者调整加载顺序,我们可以对自动配置进行更加细粒度的调整和控制。
基于条件的自动配置
基于条件的自动配置来源于 Spring 框架中“基于条件的配置”这一特性。在 Spring 框架中,我们可以使用 @Conditional 这个 Annotation 配合 @Configuration 或者 @Bean 等 Annotation 来干预一个配置或者 bean 定义是否能够生效,其最终实现的效果或者语义类似于如下伪代码:
if(符合 @Conditional 规定的条件){
加载当前配置(enable current Configuration)或者注册当前bean定义;
}要实现基于条件的配置,我们只要通过 @Conditional 指定自己的 Condition 实现类就可以了(可以应用于类型 Type 的标注或者方法 Method 的标注):
@Conditional({MyCondition1.class, MyCondition2.class, ...})最主要的是,@Conditional 可以作为一个 Meta Annotation 用来标注其他 Annotation 实现类,从而构建各色的复合 Annotation,比如 SpringBoot 的 autoconfigure 模块就基于这一优良的革命传统,实现了一批 Annotation(位于 org.springframework.boot.autoconfigure.condition 包下),条件注解如下:
@ConditionalOnBean:当容器里有指定的 Bean 的条件下。@ConditionalOnClass:当类路径下有指定的类的条件下。@ConditionalOnExpression:基于 SpEL 表达式作为判断条件。@ConditionalOnJava:基于 JVM 版本作为判断条件。@ConditionalOnJndi:在 JNDI 存在的条件下查找指定的位置。@ConditionalOnMissingBean:当容器里没有指定 Bean 的情况下。@ConditionalOnMissingClass:当类路径下没有指定的类的条件下。@ConditionalOnNotWebApplication:当前项目不是 Web 项目的条件下。@ConditionalOnProperty:指定的属性是否有指定的值。@ConditionalOnResource:类路径是否有指定的值。@ConditionalOnSingleCandidate:当指定 Bean 在容器中只有一个,或者虽然有多个但是指定首选的 Bean。@ConditionalOnWebApplication:当前项目是 Web 项目的条件下。
有了这些复合 Annotation 的配合,我们就可以结合 @EnableAuto-Configurationn 实现基于条件的自动配置了。
SpringBoot 能够风靡,很大一部分功劳需要归功于它预先提供的一系列自动配置的依赖模块,而这些依赖模块都是基于以上 @Conditional 复合 Annotation 实现的,这也意味着所有的这些依赖模块都是按需加载的,只有符合某些特定条件,这些依赖模块才会生效,这也就是我们所谓的“智能”自动配置。
调整自动配置的顺序
在实现自动配置的过程中,除了可以提供基于条件的配置,我们还可以对当前要提供的配置或者组件的加载顺序进行相应调整,从而让这些配置或者组件之间的依赖分析和组装可以顺利完成。
我们可以使用 @org.springframework.boot.autoconfigure.AutoConfigureBefore 或者 @org.springframework.boot.autoconfigure.AutoConfigureAfter 让当前配置或者组件在某个其他组件之前或者之后进行,比如,假设我们希望某些 JMX 操作相关的 bean 定义在 MBeanServer 配置完成之后进行,那么我们就可以提供一个类似如下的配置:
@Configuration
@AutoConfigureAfter(JmxAutoConfiguration.class)
public class AfterMBeanServerReadyConfiguration {
@AutoWired
MBeanServer mBeanServer;
//通过 @Bean 添加必要的 bean 定义
}至此,我们对 SpringBoot 的核心组件完成了基本的剖析,综合来看,大部分的东西都是 Spring 框架背后原有的一些概念和实践方式,SpringBoot 只是在这些概念和实践方式上对特定的场景实现进行了固化和升华,而也恰恰是这些固化让我们开发基于 Spring 框架的应用更加方便高效。
Spring-Boot-Starter常用依赖模块详解
一般认为,SpringBoot 微框架从两个主要层面影响 Spring 社区的开发者们:
- 基于 Spring 框架的“约定优先于配置(COC)”理念以及最佳实践之路。
- 提供了针对日常企业应用研发各种场景的 spring-boot-starter 自动配置依赖模块,如此多“开箱即用”的依赖模块,使得开发各种场景的 Spring 应用更加快速和高效。
SpringBoot 提供的这些“开箱即用”的依赖模块都约定以 spring-boot-starter- 作为命名的前缀,并且皆位于 org.springframework.boot 包或者命名空间下(虽然 SpringBoot 的官方参考文档中提到不建议大家使用 spring-boot-starter- 来命名自己写的类似的自动配置依赖模块,但实际上,配合不同的 groupId,这不应该是什么问题)。
如果我们访问 http://start.spring.io,并单击图 1 中的“Switch to the full version”链接,就会发现 SpringBoot1.3.2 默认支持和提供了大约 80 多个自动配置依赖模块。
图 1 Spring Initializr示意图
鉴于数量如此之多,并且也不是所有人都会在任何一个应用中用到所有,这里我们只对几个常见的通用 spring-boot-starter 模块进行讲解,希望大家可以举一反三,灵活应用所有日后工作过程中将会用到的那些 spring-boot-starter 模块。
所有的 spring-boot-starter 都有约定俗成的默认配置,但允许我们调整这些配置以改变默认的配置行为,即“约定优先于配置”。在介绍相应的 spring-boot-starter 的默认配置(约定)以及可调整配置之前,我们有必要对 SpringBoot 应用的配置约定先做一个简单的介绍。
spring-boot-starter-logging和spring-boot-starter-web
本节主要讲解 spring-boot-starter-logging 和 spring-boot-starter-web 两个常见通用的 spring-boot-starter 模块。
应用日志和spring-boot-starter-logging
Java 的日志系统多种多样,从 java.util 默认提供的日志支持,到 log4j,log4j2,commons logging 等,复杂繁多,所以,应用日志系统的配置就会比较特殊,从而 spring-boot-starter-logging 也比较特殊一些,下面将其作为我们第一个了解的自动配置依赖模块。
假如 maven 依赖中添加了 spring-boot-starter-logging,如以下代码所示:
<dependency>
<groupId> org.springframework.boot </groupId>
<artifactId> spring-boot-starter-logging </artifactId>
</dependency>那么,我们的 SpringBoot 应用将自动使用 logback 作为应用日志框架,SpringBoot 启动的时候,由 org.springframework.boot.logging.Logging-Application-Listener 根据情况初始化并使用。
SpringBoot 为我们提供了很多默认的日志配置,所以,只要将 spring-boot-starter-logging 作为依赖加入到当前应用的 classpath,则“开箱即用”,不需要做任何多余的配置,但假设我们要对默认 SpringBoot 提供的应用日志设定做调整,则可以通过几种方式进行配置调整:
- 遵循 logback 的约定,在 classpath 中使用自己定制的 logback.xml 配置文件。
- 在文件系统中任何一个位置提供自己的 logback.xml 配置文件,然后通过 logging.config 配置项指向这个配置文件来启用它,比如在 application.properties 中指定如下的配置。
logging.config=/{some.path.you.defined}/any-logfile-name-I-like.logSpringBoot 默认允许我们通过在配置文件或者命令行等方式使用 logging.file 和 logging.path 来自定义日志文件的名称和存放路径,不过,这只是允许我们在 SpringBoot 框架预先定义的默认日志系统设定的基础上做有限的设置,如果我们希望更灵活的配置,最好通过框架特定的配置方式提供相应的配置文件,然后通过 logging.config 来启用。
如果大家更习惯使用 log4j 或者 log4j2,那么也可以采用类似的方式将它们对应的 spring-boot-starter 依赖模块加到 Maven 依赖中即可:
<dependency>
<groupId> org.springframework.boot </groupId>
<artifactId> spring-boot-starter-log4j </artifactId>
</dependency>或者
<dependency>
<groupId> org.springframework.boot </groupId>
<artifactId> spring-boot-starter-log4j2 </artifactId>
</dependency>但一定不要将这些完成同一目的的 spring-boot-starter 都加到依赖中。
快速 Web 应用开发与 spring-boot-starter-web
在这个互联网时代,使用 Spring 框架除了开发少数的独立应用,大部分情况下实际上在使用 SpringMVC 开发 web 应用,为了帮我们简化快速搭建并开发一个 Web 项目,SpringBoot 为我们提供了 spring-boot-starter-web 自动配置模块。
只要将 spring-boot-starter-web 加入项目的 maven 依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>我们就得到了一个直接可执行的 Web 应用,当前项目下运行 mvn spring-boot:run 就可以直接启动一个使用了嵌入式 tomcat 服务请求的 Web 应用,只不过,我们还没有提供任何服务 Web 请求的 Controller,所以,访问任何路径都会返回一个 SpringBoot 默认提供的错误页面(一般称其为 whitelabel error page),我们可以在当前项目下新建一个服务根路径 Web 请求的 Controller 实现:
@RestController
public class IndexController {
@RequestMapping("/")
public String index() {
return "hello, there";
}
}重新运行 mvn spring-boot:run 并访问 http://localhost:8080,错误页面将被我们的 Controller 返回的消息所替代,一个简单的 Web 应用就这样完成了。
但是,简单的背后,其实却有很多“潜规则”(约定),我们只有充分了解了这些“潜规则”,才能更好地应用 spring-boot-starter-web。
项目结构层面的约定
项目结构层面与传统打包为 war 的 Java Web 应用的差异在于,静态文件和页面模板的存放位置变了,原来是放在 src/main/webapp 目录下的一系列资源,现在都统一放在 src/main/resources 相应子目录下,比如:
src/main/resources/static用于存放各类静态资源,比如 css,js 等。src/main/resources/templates用于存放模板文件,比如 *.vm。
当然,如果还是希望以 war 包的形式,而不是 SpringBoot 推荐使用的独立 jar 包形式发布 Web 应用,也可以继续原来 Java Web 应用的项目结构约定。
SpringMVC 框架层面的约定和定制
spring-boot-starter-web 默认将为我们自动配置如下一些 SpringMVC 必要组件:
- 必要的 ViewResolver,比如 ContentNegotiatingViewResolver 和 Bean-NameViewResolver。
- 将必要的 Converter、GenericConverter 和 Formatter 等 bean 注册到 IoC 容器。
- 添加一系列的 HttpMessageConverter 以便支持对 Web 请求和相应的类型转换。
- 自动配置和注册 MessageCodesResolver。
- 其他。
任何时候,如果我们对默认提供的 SpringMVC 组件设定不满意,都可以在 IoC 容器中注册新的同类型的 bean 定义来替换,或者直接提供一个基于 WebMvcConfigurerAdapter 类型的 bean 定义来定制,甚至直接提供一个标注了 @EnableWebMvc 的 @Configuration 配置类完全接管所有 SpringMVC 的相关配置,自己完全重新配置。
spring-boot-starter-jdbc与数据访问
大部分 Java 应用都需要访问数据库,尤其是服务层,所以,SpringBoot 会为我们自动配置相应的数据访问设施。
若想 SpringBoot 为我们自动配置数据访问的基础设施,那么,我们需要直接或者间接地依赖 spring-jdbc,一旦 spring-jdbc 位于我们 SpringBoot 应用的 classpath,即会触发数据访问相关的自动配置行为,最简单的做法就是把 spring-boot-starter-jdbc 加为应用的依赖。
默认情况下,如果我们没有配置任何 DataSource,那么,SpringBoot 会为我们自动配置一个基于嵌入式数据库的 DataSource,这种自动配置行为其实很适合于测试场景,但对实际的开发帮助不大,基本上我们会自己配置一个 DataSource 实例,或者通过自动配置模块提供的配置参数对 DataSource 实例进行自定义的配置。
假设我们的 SpringBoot 应用只依赖一个数据库,那么,使用 DataSource 自动配置模块提供的配置参数是最方便的:
spring.datasource.url=jdbc:mysql://{database host}:3306/{databaseName}
spring.datasource.username={database username}
spring.datasource.password={database password}当然,自己配置一个 DataSource 也是可以的,SpringBoot 也会智能地选择我们自己配置的这个 DataSource 实例(只不过必要性真不大)。
除了 DataSource 会自动配置,SpringBoot 还会自动配置相应的 JdbcTemplate、DataSourceTransactionManager 等关联“设施”,可谓服务周到,我们只要在使用的地方注入就可以了:
class SomeDao {
@Autowired
JdbcTemplate jdbcTemplate;
public <T> List<T> queryForList(String sql){
// ...
}
// ...
}不过,spring-boot-starter-jdbc 以及与其相关的自动配置也不总是带来便利,在某些场景下,我们可能会在一个应用中需要依赖和访问多个数据库,这个时候就会出现问题了。
假设我们在 ApplicationContext 中配置了多个 DataSource 实例指向多个数据库:
@Bean
public DataSource dataSource1() throws Throwable {
DruidDataSource dataSource = new DruidDataSource();
dataSource.setUrl(...);
dataSource.setUsername(...);
dataSource.setPassword(...);
// TODO other settings if necessary in the future.
return dataSource;
}
@Bean
public DataSource dataSource2() throws Throwable {
DruidDataSource dataSource = new DruidDataSource();
dataSource.setUrl(...);
dataSource.setUsername(...);
dataSource.setPassword(...);
// TODO other settings if necessary in the future.
return dataSource;
}那么,不好意思,启动 SpringBoot 应用的时候会抛出类似如下的异常(Exception):
Exception):No qualifying bean of type [javax.sql.DataSource] is defined: expected single matching bean but found 2
为了避免这种情况的发生,我们需要在 SpringBoot 的启动类上做点儿“手脚”:
@SpringBootApplication(exclude = { DataSourceAutoConfiguration.class, DataSourceTransactionManagerAutoConfiguration.class })
public class UnveilSpringChapter3Application {
public static void main(String[] args) {
SpringApplication.run(UnveilSpringChapter3Application.class, args);
}
}也就是说,我们需要在这种场景下排除掉对 SpringBoot 默认提供的 DataSource 相关的自动配置。但如果我们还是想要享受 SpringBoot 提供的自动配置 DataSource 的机能,也可以通过为其中一个 DataSource 配置添加 org.springframework.context.annotation.Primary 这个 Annotation 的方式以实现两全其美:
@Bean
@Primary
public DataSource dataSource1() throws Throwable {
DruidDataSource dataSource = new DruidDataSource();
dataSource.setUrl(...);
dataSource.setUsername(...);
dataSource.setPassword(...);
// TODO other settings if necessary in the future.
return dataSource;
}
@Bean
public DataSource dataSource2() throws Throwable {
DruidDataSource dataSource = new DruidDataSource();
dataSource.setUrl(...);
dataSource.setUsername(...);
dataSource.setPassword(...);
// TODO other settings if necessary in the future.
return dataSource;
}另外,SpringBoot 还提供了很多其他数据访问相关的自动配置模块,比如 spring-boot-starter-data-jpa、spring-boot-starter-data-mongodb 等,大家可以根据自己数据访问的具体场景选择使用这些自动配置模块。
如果选择了 spring-boot-starter-data-jpa 等关系数据库相关的数据访问自动配置模块,并且还需要同时依赖访问多个数据库,那么,也需要相应的在 SpringBoot 启动类中排除掉这些自动配置模块中的 AutoConfiguration 实现类(对应 spring-boot-starter-data-jpa 是 JpaRepositoriesAutoConfiguration),或者标注某个 DataSource 为 @Primary。
SpringBoot 应用的数据库版本化管理
关于如何针对数据库的变更进行版本化管理,从 Ruby On Rails 的 migration 支持,到 Java 的 MyBatis Migrations,Flyway 以及 Liquibase,都给出了相应的最佳实践建议和方案。
但是,数据库 migrations 的实践方式并没有在国内普遍应用起来,大部分都是靠人来解决,这或许可以用一句“成熟度不够”来解释,另外一个原因或许是职能明确分工后造成的局面。
如果仔细分析以上数据库 migration 方案就会发现,它们给出的应用场景和实践几乎都是单应用、单部署的,这在庞大单一部署单元(Monolith)的年代显然是很适合的,因为应用从开发到发布部署,再到启动,整个生命周期内,应用相关的所有“原材料”都集中在一起进行管理,而且国外开发者往往偏“特种作战”(Full-Stack Developer),一身多能,从而数据库 migration 这种实践自然可以成型并广泛应用。
但回到国内来看,我们往往是“集团军作战”,拼的是“大部队+明确分工”的模式,而且应用所面向的服务人数也往往更为庞大,所以,整个应用的交付链路上各个环节之间的衔接是不同的人,而应用最终部署的拓扑又往往是分布式部署居多,所以,在一个项目单元里维护数据库的 migration 脚本然后部署后启动前执行这些脚本就变得不合时宜了:
1)从职责上,这些 migration 脚本虽然大部分情况下都是开发人员写,但写完之后要不要进行 SQL 审查,是否符合规范,这些又会涉及应用运维 DBA。
代码管理系统对开发来说很亲切,对 DBA 来说则不尽然,而且 DBA 往往还要一人服务多个团队多个项目,从 DBA 的角度来说,他更愿意将 SQL 集中到一处进行管理,而不是分散在各个项目中。
2)应用分布式部署之后,就不单单是单一部署在应用启动的之前直接执行一次 migration 脚本那么简单了,你要执行多次,虽然 migration 方案都有版本控制,变更应该最终状态都是一样的,但这多个部署节点上都执行同一逻辑显然是多余的。
更复杂一点儿,多个应用可能同时使用同一个数据库的情况,一个项目的数据库 migration 操作跟另一个项目的数据库 migration 操作会不会在互不知晓的情况下产生冲突和破坏?
所以,数据库 migration 的思路和实践很好,但不能照搬(任何事情其实皆如此),不过,我们可以结合现有的一些数据库 migration 方案,比如 flyway 或者 liquibase,我们可以对这些数据库 migration 的基础设施和支持外部化(Externalize),一个可能的架构如图 1 所示。
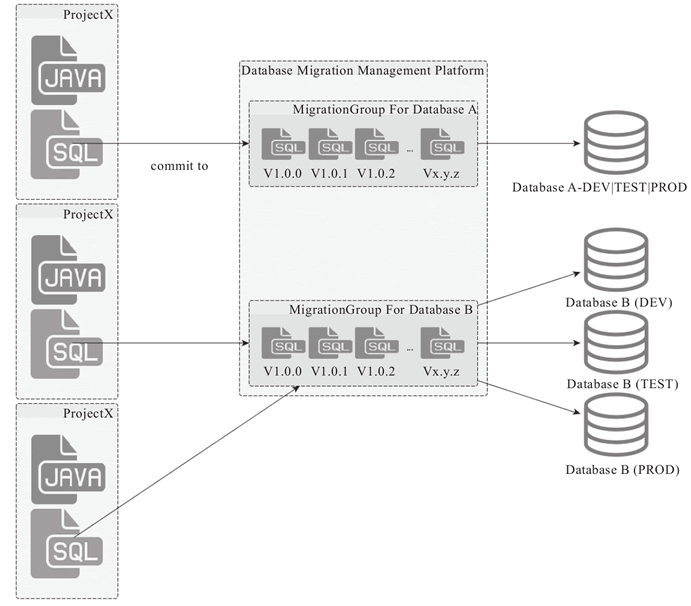
图 1 集中管控的数据库 Migration 架构示意图
在这个架构中,数据库 migration 的版本化管理剥离到了单独的管理系统,单一项目中不再保存完整历史的 migration 记录,而只需要提供当次发布要牵扯的数据库变更 SQL。
在项目发布的时候,由 DBA 进行统一的审查并纳入单独的数据库 migration 管理系统,由单独的数据库 migration 管理系统来管理完整的数据库 migration 记录,可以根据数据库的粒度进行管理和状态同步,从而既可以在开发阶段让开发人员可以集中管理数据库 SQL,又能在发布期间审查 SQL 并同步 migration 状态和完整的历史记录管理。
当然,这一切可以实现的前提是有一套完整的软件交付链路支撑平台,能够从流程上,软件生命周期管理上进行统一的治理和规范,后面教程中会跟大家做进一步深入的探讨。
不管怎么样,SpringBoot 还是为大家提供了针对 Flyway 和 Liquibase 的自动配置功能(org.springframework.boot.autoconfigure.flyway.FlywayAutoConfiguration 和 org.springframework.boot.autoconfigure.liquibase.LiquibaseAutoConfiguration),对于单一开发和部署的应用来说,还是可以考虑的。
